
La web_search skill d’un agent IA ouvre un accès direct au web en temps réel. Mais cet accès ne vaut que ce que vaut le fournisseur configuré derrière. Un mauvais choix se traduit par des réponses en retard, des données tronquées, ou des pages qui ne chargent jamais faute de rendu JavaScript. Et une fois vos agents en autonomie, les coûts d’API montent vite : plusieurs équipes ont découvert des factures à trois chiffres après quelques jours de tests intensifs.
Ce comparatif passe en revue les 7 principaux fournisseurs de recherche pour agent IA en 2026 : ce que chacun retourne, ses limites concrètes, la tarification réelle et dans quel cas précis l’utiliser. Si vous débutez avec les agent IA, cet article couvre l’architecture et les cas d’usage concrets avant de choisir vos outils.
À retenir avant de commencer
- Brave Search : crédit mensuel renouvelable de 5 $ (env. 1 000 requêtes), sans abonnement obligatoire
- Tavily : 1 000 recherches gratuites/mois, JSON structuré natif, idéal pour les pipelines IA
- SearXNG auto-hébergé : requêtes illimitées, conformité RGPD maximale, frais d’hébergement à partir de 3,49 €/mois
Les trois options permettent de lancer un premier agent fonctionnel sans budget conséquent. La différence se joue sur la qualité et la fraîcheur des données web auxquelles l’agent peut accéder.
Transformer les sites web vers Excel, CSV, Google Sheets ou base de données.
Auto-détecter les sites web et extraire les données sans aucun codage.
Scraper les sites populaires en quelques clics avec les modèles pré-construits.
Ne se trouver jamais bloqué grâce aux proxies IP rotatifs et à l’API avancée.
Service Cloud pour programmer le scraping de données et automatiser vos workflows IA.
Pourquoi le fournisseur de recherche est votre premier maillon critique
Un agent IA, c’est un modèle qui n’attend plus vos instructions : il planifie une séquence de tâches, les exécute, vérifie les résultats et recommence si nécessaire. Là où ChatGPT ou Claude.ai vous donnent une réponse, un agent prend une décision et agit.
En pratique, le fournisseur de recherche n’est pas un détail de configuration. C’est le premier maillon de votre pipeline de données agentique. Si vos agents cherchent des prix concurrents, vérifient des informations en temps réel ou alimentent un CRM, la qualité de ce premier appel conditionne tout ce qui suit.
Le contexte en chiffres
- Le marché mondial de l’IA agentique croît à 45,8 % par an, avec une projection supérieure à 50 milliards de dollars en 2030.
- 82 % des organisations prévoient d’intégrer l’IA agentique dans les 1 à 3 prochaines années.
- L’usage des agents dans les logiciels d’entreprise passera de 1 % (2024) à 33 % (2028).
- En France, les feuilles de route publiées en 2025-2026 par France Stratégie et le Comité de l’IA de l’État positionnent l’IA agentique comme levier prioritaire pour la compétitivité des ETI et des grands groupes.
Comment fonctionne la recherche web dans un agent IA
Trois problèmes reviennent systématiquement dans les retours d’équipes françaises qui déploient des agents IA en production : les coûts API qui s’emballent sur les gros volumes, les résultats en retard sur les sites à fort JavaScript, et la question de la localisation des données pour les projets soumis au RGPD. Le choix du fournisseur de recherche est souvent la première variable sur laquelle agir.
Un fournisseur de recherche est le service externe qui alimente l’outil web_search dans votre agent. Deux outils travaillent de concert :
- web_search : envoie une requête à votre fournisseur configuré et retourne jusqu’à 5 résultats (titre, URL, snippet) par défaut, mis en cache 15 minutes. Nécessite une clé API valide.
- web_fetch : récupère le contenu brut d’une URL via requête HTTP GET. N’exécute pas le JavaScript ; les pages qui dépendent du rendu côté client retourneront un contenu incomplet ou vide.
Les deux outils fonctionnent souvent en tandem : web_search identifie les URLs pertinentes, web_fetch extrait le contenu de ces pages. Votre choix de fournisseur détermine la qualité de cette première étape.

Deux types d’intégration existent :
- Fournisseurs natifs : configurés directement dans votre agent. Inclut Brave, Gemini, Grok, Perplexity, DuckDuckGo, Firecrawl et Tavily.
- Fournisseurs via Skill/MCP : installés en complément. SearXNG fonctionne actuellement ainsi.
Ordre de détection automatique quand plusieurs clés sont configurées : Brave > Gemini > Grok > Perplexity > Firecrawl > Tavily. La première clé valide trouvée est utilisée.
La combinaison web_search + web_fetch vous amène jusqu’à la page, puis s’arrête. Pour des lectures ponctuelles, c’est suffisant. Mais dès que votre agent doit boucler sur des listes de produits, extraire des champs structurés ou surveiller des dizaines de pages en planification, vous faites du web scraping, et le fournisseur de recherche n’est que la première étape.
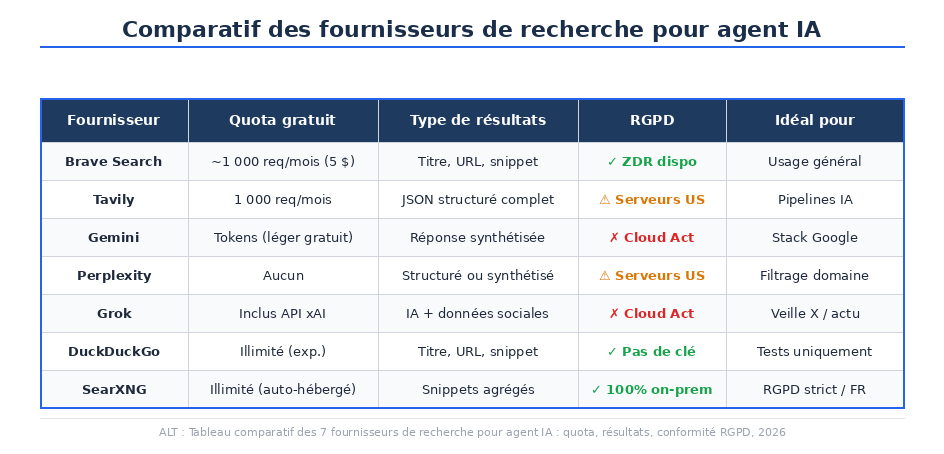
Tableau comparatif : les 7 meilleurs fournisseurs
Deux outils émergents méritent d’être signalés, même si leur intégration native reste limitée en 2026. Exa.ai adopte une approche de recherche sémantique : au lieu de faire correspondre des mots-clés, il identifie des pages similaires par sens, ce qui donne des résultats souvent plus pertinents pour les workflows IA complexes.
Jina AI Reader propose un endpoint gratuit : il suffit de préfixer n’importe quelle URL cible avec https://r.jina.ai/ pour obtenir un texte propre, immédiatement exploitable par votre LLM.
Les deux outils s’intègrent bien en complément d’un pipeline Brave + Tavily sur les cas d’usage avancés.
Tous les fournisseurs retournent des URLs et des snippets. Aucun ne gère l’étape aval d’extraction de données structurées depuis ces pages. Si vous avez besoin d’extraire des données produits, des listes de leads ou des inventaires, rendez-vous directement à la section ‘Après la recherche’.
Brave Search API : le fournisseur par défaut pour votre agent IA
Brave est le fournisseur par défaut et l’option la mieux documentée. Il s’appuie sur son propre index indépendant, pas Google ni Bing, ce qui en fait un choix solide pour la confidentialité dans un usage général de recherche web via API.
Ce qu’il fait bien
- Recherche privacy-first avec filtrage pays et langue fiable, natif en français (fr, en, de, ja).
- Filtres de fraîcheur et plages de dates (freshness: ‘week’, date_after, date_before) pour les agents orientés actualités.
- Documentation et support communautaire les meilleurs parmi tous les fournisseurs.
- Index indépendant de 30 milliards de pages, mis à jour par plus de 100 millions d’actualisations quotidiennes.
- Conforme RGPD : Zero Data Retention (ZDR) disponible pour les entreprises, un argument fort pour les équipes européennes.
- Pour les équipes qui connectent Brave à un pipeline MCP, le guide sur le protocole MCP détaille les configurations compatibles.
Où ça coince
- Retourne uniquement des snippets, pas de contenu de page complet. Les agents ayant besoin du texte de la page doivent faire un appel web_fetch supplémentaire par résultat.
- Le mode llm-context ignore silencieusement plusieurs paramètres de filtrage.
- Sur les volumes moyens (5 000 à 20 000 requêtes/mois), le passage au plan payant peut représenter entre 25 $ et 100 $/mois selon les pics d’activité. À budgéter en amont si vos agents tournent en continu.
Tarification réelle (2026) :
L’ancien plan gratuit sans carte bancaire n’existe plus pour les nouveaux inscrits depuis février 2026. Chaque nouveau compte reçoit un crédit mensuel renouvelable de 5 $ (environ 1 000 requêtes). Fixez votre plafond à 5 $ dans le tableau de bord Brave pour éviter toute facturation surprise. Au-delà : 5 $ par tranche de 1 000 requêtes.
Configuration :
{
"tools": {
"web": {
"search": {
"provider": "brave",
"apiKey": "YOUR_BRAVE_API_KEY",
"maxResults": 5,
"timeoutSeconds": 30
}
}
}
}Tavily : recherche structurée et pipelines IA
Tavily est conçu spécifiquement pour les workflows d’agents IA, retournant des réponses JSON structurées avec le contenu complet des pages. Cela réduit ou élimine le besoin d’appels web_fetch supplémentaires, un gain de vitesse et de coût significatif pour les pipelines de recherche intensifs.
Il fonctionne à la fois comme fournisseur natif et comme Skill, ce qui donne accès à cinq outils dédiés : tavily_search, tavily_extract, tavily_crawl, tavily_map, tavily_research.
Ce qu’il fait bien
- Extraction directe de réponses, idéal pour la veille concurrentielle et la vérification de faits.
- Profondeur de recherche avancée pour une couverture multi-sources exhaustive.
- Filtrage par domaine pour des sources fiables et curées.
- JSON structuré natif, sans post-traitement supplémentaire.
Où ça coince
- Nécessite une installation via Skill pour la suite complète d’outils.
- Peut entrer en conflit avec le fournisseur web_search natif si les deux sont configurés simultanément.
Tarification : 1 000 recherches gratuites par mois. Environ 0,008 $ par recherche au-delà.
En pratique : Tavily excelle dans les sorties structurées. C’est l’évolution naturelle pour les agents de recherche intensive : veille concurrentielle, vérification de faits, synthèse multi-sources. Tavily s’intègre aussi bien dans un pipeline n8n que dans un agent Claude ou ChatGPT. Si vous partez de zéro, cet article vous guide pas à pas : comment créer un agent IA.
Installation via Skill :
/skill install @anthropic/tavily-searchOu comme fournisseur natif :
{
"tools": {
"web": {
"search": {
"provider": "tavily",
"tavily": {
"apiKey": "tvly-your-api-key"
}
}
}
}
}Gemini : quand votre agent IA tourne déjà sur Google Cloud
Gemini utilise l’index de recherche de Google pour générer des réponses synthétisées par IA avec des citations inline. Modèle par défaut : gemini-2.5-flash. Si vous payez déjà l’accès à l’API Gemini pour des appels LLM ailleurs dans votre stack, la recherche ne génère pas de surcoût.
Ce qu’il fait bien
- Réponses synthétisées avec citations, réduit les hallucinations pour les requêtes factuelles.
- Couverture large pour les requêtes locales et longue traîne, appuyée par l’index Google.
Où ça coince
- Retourne du texte synthétisé, pas des listes structurées (titres/URLs/snippets), ce qui nécessite des ajustements de prompt pour les étapes suivantes.
- Non idéal pour les agents ayant besoin de données proprement structurées.
- Point de vigilance RGPD : les données transitent par des serveurs Google soumis au Cloud Act américain. À évaluer avec votre DPO avant tout déploiement en production.
Tarification : basé sur les tokens. Effectivement gratuit pour un usage léger si vous avez déjà un accès API Gemini.
{
"tools": {
"web": {
"search": {
"provider": "gemini",
"gemini": {
"apiKey": "AIza...",
"model": "gemini-2.5-flash"
}
}
}
}
}Perplexity : filtrage par domaine et sources francophones officielles
Perplexity se distingue par sa fonctionnalité domain_filter, qui permet de restreindre les résultats à des sources fiables comme les domaines .fr, .gouv.fr, .edu ou github.com. Cette précision le rend particulièrement précieux pour la recherche académique, technique ou sensible sur le plan de la conformité.
Ce qu’il fait bien
- Filtrage par domaine pour restreindre les résultats à des sources fiables, y compris des sources francophones officielles.
- Gestion scalable pour les tâches de recherche multi-sources volumineuses.
Où ça coince
- Une configuration en double mode qui peut dérouter lors de la première mise en place.
- Pas de plan gratuit documenté : une barrière réelle pour le prototypage.
En pratique : si votre agent doit se limiter à des sources précises (.gouv.fr, pubmed.ncbi.nlm.nih.gov, domaines académiques), Perplexity est le seul fournisseur qui gère ça nativement. En dehors de ce cas, Brave ou Tavily sont plus adaptés.
{
"tools": {
"web": {
"search": {
"provider": "perplexity",
"perplexity": {
"apiKey": "pplx-..."
}
}
}
}
}Grok : veille temps réel sur X et les actualités de rupture
Grok exploite l’API xAI pour fournir des données en temps réel depuis des plateformes sociales comme X (anciennement Twitter) et les sources d’actualités de rupture. C’est le seul fournisseur de cette liste avec un accès natif aux données sociales.
Ce qu’il fait bien
- Accès en temps réel aux conversations sur les réseaux sociaux et aux actualités.
- Réponses synthétisées avec citations, mises à jour pour les événements courants.
Où ça coince
- Conçu pour les données sociales en temps réel, pas un remplacement du moteur de recherche général.
- L’accès aux données sociales n’a de valeur que si votre workflow en a activement besoin.
En pratique : Grok est spécialisé pour les tâches où la fraîcheur des données est non-négociable. Pour les équipes qui suivent l’actualité économique française (Les Echos, BFM Business, discussions sur X autour de mots-clés sectoriels), Grok est le seul fournisseur capable de capter ces signaux en temps réel. Utilisez-le en complément de Brave ou Tavily pour une couverture complète.
{
"tools": {
"web": {
"search": {
"provider": "grok",
"grok": {
"apiKey": "xai-...",
"model": "grok-4-1-fast"
}
}
}
}
}DuckDuckGo : zéro clé API, zéro coût, pour tester vite
DuckDuckGo est le seul fournisseur ne nécessitant aucune clé API. Il fonctionne en scrapant les pages HTML non-JavaScript de DuckDuckGo, pas une API officielle, ce qui le rend entièrement gratuit et sans configuration. Il est listé comme intégration expérimentale et non officielle.
Ce qu’il fait bien
- Zéro coût, zéro clé API : fonctionne immédiatement.
- Suffisant pour tester la web_search avant de s’engager sur un abonnement payant.
- Contrôles région et SafeSearch disponibles.
Où ça coince
- Expérimental et non officiel : DuckDuckGo peut servir des CAPTCHAs ou bloquer les requêtes sous charge automatisée.
- Pas de filtres de fraîcheur ni de filtrage pays/langue fin.
- Le parsing HTML peut casser si DuckDuckGo modifie la structure de ses pages.
En pratique : le point de départ idéal pour tester sans s’inscrire à une API payante. Pas adapté à la production ni aux volumes élevés.
{
"plugins": {
"entries": {
"duckduckgo": {
"config": {
"webSearch": {
"region": "fr-fr",
"safeSearch": "moderate"
}
}
}
}
}
}SearXNG et RGPD : la référence pour les équipes françaises
SearXNG est un métamoteur de recherche libre et open source qui agrège les résultats de plusieurs backends : Google, DuckDuckGo, Bing et bien d’autres. L’auto-hébergement vous donne des requêtes illimitées et une confidentialité totale des données. C’est l’option la plus solide pour les équipes françaises soumises à des contraintes RGPD strictes.
Ce qu’il fait bien
- Requêtes illimitées sans coût par requête, idéal pour les agents à volume élevé.
- Entièrement privé et sous votre contrôle quand auto-hébergé.
- Conformité RGPD maximale : aucune donnée ne quitte votre infrastructure.
- Communauté francophone très active, avec de nombreuses instances publiques disponibles sur searx.space.
Où ça coince
- Configuration plus longue que les options API : nécessite des compétences DevOps.
- Qualité des résultats variable selon les backends actifs.
Hébergeurs recommandés pour SearXNG (France / Europe) :
- OVHcloud : Roubaix, Gravelines, Strasbourg — leader européen, VPS à partir de 3,59 €/mois, 100 % RGPD-compliant, données hébergées en France.
- Scaleway : Paris, Amsterdam — hébergeur français, VPS DEV1-S à 3,49 €/mois, engagement RGPD fort.
- Infomaniak : Genève — hébergeur suisse, zéro tracking, 100 % énergies renouvelables.
- Hetzner : Nuremberg, Helsinki — excellent rapport qualité/prix, serveurs sous juridiction européenne.
Déploiement via Docker :
docker run -d -p 8080:8080 searxng/searxngQuel fournisseur choisir pour votre cas d’usage ?
Le bon fournisseur dépend avant tout de ce que votre agent doit faire concrètement. Voici les cas qui reviennent le plus souvent :
- Nouvelle installation / tests : commencez par DuckDuckGo (sans clé) ou Brave (mieux documenté). Ajoutez Tavily quand vous avez besoin de meilleurs résultats.
- Agents de recherche intensive (veille concurrentielle, vérification de faits, synthèse multi-sources) : Tavily comme fournisseur principal.
- Déjà abonné à l’API Gemini : utilisez la recherche Gemini, même clé API, sans surcoût. Vérifiez avec votre DPO si vous traitez des données clients.
- Recherche académique ou technique spécifique : Perplexity, spécifiquement pour domain_filter.
- Veille réseaux sociaux ou actualités urgentes : Grok.
Contexte français (RGPD, volumes élevés, LLM on-premise) : SearXNG auto-hébergé chez OVHcloud ou Scaleway s’impose dans tous ces cas. C’est la seule option à coût fixe, 100 % on-premise, compatible avec Mistral AI ou tout LLM hébergé en France. Ajoutez Brave en fallback pour la couverture générale sans quitter l’espace européen.
RGPD et souveraineté numérique : ce que ça change pour vos agents IA
En France et dans l’UE, le RGPD impose que les données personnelles traitées par vos outils respectent des règles strictes de localisation et de conservation. Le Cloud Act américain crée un risque de souveraineté pour tout service hébergé aux États-Unis. Pour les équipes françaises : Brave (ZDR disponible) et SearXNG auto-hébergé en Europe sont les options les plus solides sur le plan de la conformité. Consultez votre DPO avant de déployer Gemini ou Grok en production.
L’article 30 du RGPD impose à toute organisation de tenir un registre des activités de traitement : si vos agents IA envoient des requêtes contenant des données à caractère personnel vers un LLM externe, ce traitement doit y figurer. Par ailleurs, la CNIL a publié en 2024 ses recommandations sur les systèmes d’IA, rappelant que le recours à des fournisseurs hors UE (comme Gemini ou Grok) doit faire l’objet d’une analyse d’impact (DPIA) lorsque les données traitées sont sensibles.
Au-delà de la recherche : quand votre agent IA a besoin de données structurées
Ce que les fournisseurs de recherche ne font pas, c’est extraire.
Quand web_search trouve la page de tarification d’un concurrent et que web_fetch récupère le HTML brut, il reste encore tout le travail réel : identifier les prix, les normaliser en lignes, gérer la pagination si le catalogue fait 50 produits, et produire un fichier que votre équipe peut actionner. C’est l’écart concret entre ‘j’ai une page’ et ‘j’ai des données’.
Pour les équipes qui utilisent des assistants IA comme Claude, ChatGPT ou Cursor, Octoparse MCP (Model Context Protocol) permet de déclencher des extractions structurées depuis le chat, en langage naturel, sans quitter votre flux de travail.
Si vous utilisez Claude comme LLM principal, cet article sur le scraping web avec Claude montre comment les deux s’articulent dans un workflow concret.
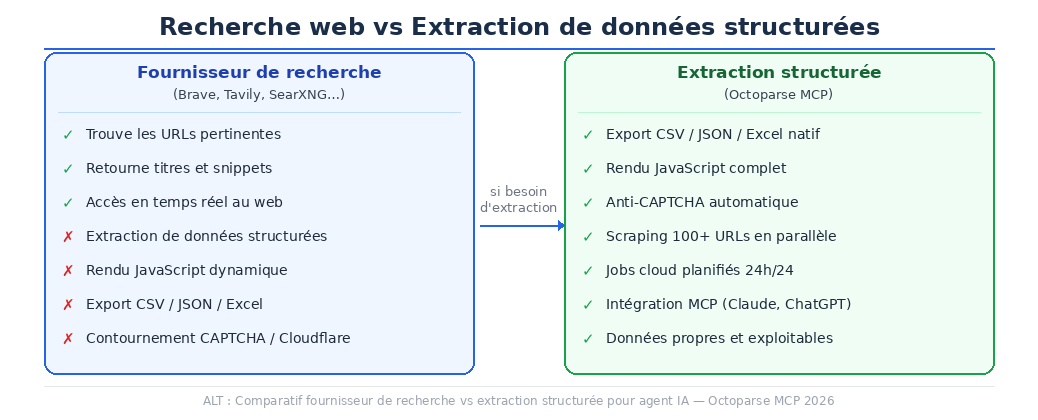
Ce qu’Octoparse fait que web_search ne fait pas
- Extraction de données structurées (CSV, JSON, Excel) directement depuis les pages de résultats.
- Rendu des sites à fort contenu JavaScript que web_fetch ne peut pas traiter.
- Contournement des CAPTCHAs et de la protection Cloudflare automatiquement.
- Scraping en masse et jobs cloud parallèles, adaptés aux agents à volume élevé.
| Tâche | Fournisseur de recherche | Octoparse |
| Trouver des URLs pertinentes | Oui — fonction principale | Non — pas son rôle |
| Retourner titres / URLs / snippets | Oui | Oui |
| Extraire des données structurées (CSV/JSON) | Non | Export natif |
| Gérer les pages JavaScript dynamiques | Échec sur la plupart | Rendu JS complet |
| Contourner Cloudflare / CAPTCHA | Non | Intégré automatiquement |
| Scraping 100+ URLs en parallèle | Non | Jobs cloud parallèles |
| Planification 24h/24 en cloud | Non — local uniquement | Cloud natif |
Connecter Octoparse via MCP prend moins de dix minutes, directement depuis Claude ou ChatGPT, sans configuration de scraper. Si vous utilisez déjà le Octoparse via MCP dans votre stack, c’est une extension immédiate : aucune infrastructure supplémentaire n’est requise.
Template recommandé :
https://www.octoparse.fr/template/universal-content
Conclusion
Aucun fournisseur ne s’impose à toutes les situations. Brave est le point de départ logique, Tavily prend le relais dès que vos pipelines ont besoin de JSON structuré, et SearXNG s’impose dès que la souveraineté des données n’est pas négociable. Mesurez vos volumes réels avant de vous engager sur un plan payant.
Ce que ces fournisseurs ne font pas, c’est transformer les pages trouvées en données exploitables. C’est précisément là qu’Octoparse et son intégration MCP interviennent, directement depuis votre agent, sans infrastructure supplémentaire.
Si vous en êtes à la phase de construction, cet article sur la création d’un agent IA part des bases et couvre les choix d’outils jusqu’à la mise en production. Pour ceux qui hésitent entre frameworks, la comparaison OpenClaw vs Claude Code pose les bons critères de choix.
FAQ
- Existe-t-il un fournisseur de recherche totalement gratuit pour un agent IA ?
Oui, plusieurs options existent. DuckDuckGo ne nécessite aucune clé API et fonctionne immédiatement (expérimental, déconseillé en production). Brave inclut un crédit mensuel renouvelable de 5 $ (environ 1 000 requêtes). Tavily offre 1 000 recherches gratuites par mois. SearXNG est entièrement gratuit en auto-hébergement, avec uniquement des frais d’hébergement (à partir de 3,49 €/mois chez Scaleway).
- La web_search skill fonctionne-t-elle sans clé API ?
En général non. Sans fournisseur configuré, web_search retourne une erreur de configuration. DuckDuckGo est l’exception : il ne nécessite pas de clé car il scrappe directement les pages publiques DuckDuckGo.
- À quoi sert la web_search skill dans un agent IA ?
La web_search skill donne à l’agent un accès au web en temps réel, sans avoir à pré-charger toutes les connaissances dans le prompt système. La skill interroge votre fournisseur configuré, récupère titres, URLs et snippets, et les met à disposition de l’agent. Pour le contenu complet d’une page, web_fetch est utilisé en complément. Pour de l’extraction de données structurées en production, un outil dédié comme Octoparse est nécessaire.
- Quel fournisseur est utilisé par défaut ?
La détection est automatique en fonction des variables d’environnement disponibles, dans cet ordre : Brave > Gemini > Grok > Perplexity > Firecrawl > Tavily. La première clé valide trouvée est utilisée. Si aucune clé n’est configurée, web_search retourne une erreur. Lancez openclaw doctor après la configuration : cette commande vérifie que votre clé API est bien reconnue et que la connexion au fournisseur est opérationnelle.
- Puis-je changer de fournisseur en cours de projet ?
Oui. Mettez à jour la valeur du fournisseur dans openclaw.json (ou échangez la variable d’environnement) et redémarrez votre agent. Aucune migration de données n’est requise. Lancez openclaw doctor après le changement pour vérifier la connectivité.
- Brave Search API est-elle vraiment gratuite ?
Plus au sens strict pour les nouveaux inscrits depuis février 2026. Le système actuel offre un crédit mensuel renouvelable de 5 $ (environ 1 000 requêtes) à tous les nouveaux comptes. Les abonnements legacy restent valides. Fixez votre plafond de consommation à 5 $ dans le tableau de bord Brave pour un usage effectivement gratuit.
- SearXNG est-il adapté à une équipe française soumise au RGPD ?
Oui, c’est précisément le cas d’usage le plus fort de SearXNG. Auto-hébergé chez OVHcloud, Scaleway ou Infomaniak, toutes les données restent sur des serveurs européens, sans aucune transmission à des tiers américains soumis au Cloud Act. Consultez votre DPO pour confirmer que cette architecture correspond à vos exigences de conformité spécifiques.
- Comment un agent IA se compare-t-il à un outil de web scraping classique ?
Un agent IA aborde le web de manière conversationnelle : vous décrivez ce que vous voulez, et l’agent détermine comment l’obtenir, idéal pour des tâches ponctuelles. Un outil de web scraping dédié comme Octoparse est optimisé pour l’extraction structurée et répétable à grande échelle : fiable sur 100+ URLs, sites à fort JavaScript, et pipelines planifiés 24h/24. Les deux approches sont complémentaires : l’agent gère le raisonnement et l’orchestration, l’outil de scraping gère le volume et la structuration des données.
- L’AI Act européen a-t-il un impact sur l’utilisation d’un agent IA en France ?
Oui, indirectement. L’AI Act (entrée en application progressive depuis 2024) impose des obligations de transparence et de traçabilité pour les systèmes d’IA à risque élevé. Si vous déployez un agent IA dans un contexte professionnel sensible (RH, finance, santé), documentez les sources de données utilisées et vérifiez avec votre DPO que votre configuration respecte les obligations de l’article 13. Pour un usage interne de veille ou de collecte de données, le niveau de risque reste en général faible.
- Peut-on utiliser Qwant comme fournisseur de recherche pour un agent IA ?
Pas nativement en 2026. Qwant ne propose pas d’API de recherche publique ouverte aux développeurs dans les mêmes conditions que Brave ou Tavily. Pour les équipes qui souhaitent absolument un moteur français, SearXNG auto-hébergé avec Qwant comme backend est la solution la plus proche : SearXNG peut interroger Qwant parmi ses sources agrégées. C’est aussi la configuration la plus solide sur le plan RGPD.
- Quelle est la différence entre web_search et web_fetch dans un agent IA ?
web_search interroge votre fournisseur configuré et retourne une liste de résultats (titre, URL, snippet). web_fetch récupère le contenu brut d’une URL spécifique via HTTP GET, sans exécuter le JavaScript. Les deux outils sont complémentaires : web_search identifie les pages pertinentes, web_fetch en récupère le contenu.
- L’utilisation d’une API de recherche dans un agent IA est-elle conforme au RGPD ?
Cela dépend du fournisseur et de la nature des données traitées. Brave (avec l’option ZDR) et SearXNG auto-hébergé en Europe sont les deux seules options permettant de garantir qu’aucune donnée ne quitte l’espace européen. Pour Gemini et Grok, les données transitent par des serveurs américains soumis au Cloud Act, ce qui peut poser problème si vos agents traitent des données à caractère personnel. La règle pratique : si votre agent recherche des informations générales (prix publics, actualités), le risque est faible. Si les requêtes contiennent des données clients ou des informations sensibles, une DPIA et l’avis de votre DPO sont nécessaires.
- Quel est le coût mensuel réel d’un agent IA actif en production ?
Tout dépend du volume de requêtes. Un agent qui tourne avec 200 appels web_search par jour (soit 6 000/mois) représente environ 30 $ chez Brave ou Tavily. À 1 000 appels/jour (30 000/mois), la facture peut atteindre 150 $. SearXNG auto-hébergé sur un VPS Scaleway à 3,49 €/mois reste la seule option à coût fixe, quel que soit le volume. Posez systématiquement un plafond de dépense dans le tableau de bord de votre fournisseur avant de passer en production.
发表回复