
XPath (XML Path Language) est un langage de requête pour localiser des éléments dans un document XML/HTML, vous permettant de localiser un élément dans l’ensemble du document de manière précise et rapide. Cet article cherche à donner une introduction de XPath, accompagnée des expressions XPath et des XPath exemples d’application pour vous montrer comment l’utiliser pour récupérer correctement et précisément les données dont vous avez besoin.
1. Qu’est-ce que XPath
XPath (XML Path Language) est un langage de requête pour sélectionner des éléments dans un document XML/HTML, vous permettant de localiser un élément dans l’ensemble du document de manière précise et rapide.
De manière générale, les pages Web sont écrites avec un langage appelé HTML. Si vous chargez une page Web dans un navigateur (Chrome, Firefox, etc.), vous pouvez facilement accéder au document HTML correspondant en appuyant sur la touche F12. Tout ce que vous voyez sur la page web peut être lu dans le HTML, tel que les images, des blocs de texte, des liens, des menus, etc. comme ce qui montre ce tableau ci-dessous.
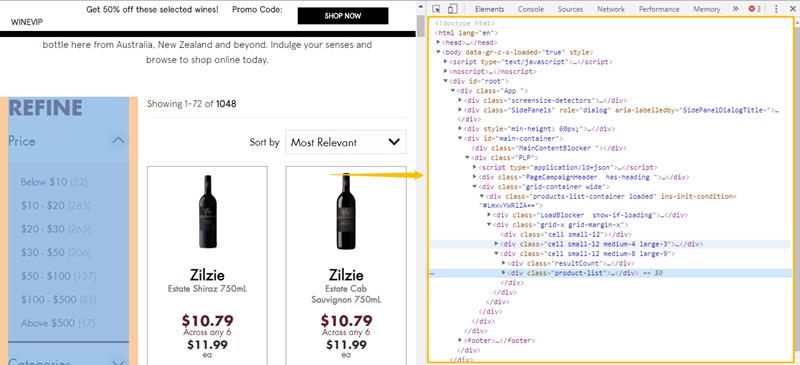
XPath est le langage le plus largement utilisé quand on a besoin de localiser un élément dans un document HTML. C’est pourquoi on peut considérer le XPath comme le “chemin” qui nous conduit vers l’élément cible dans le document HTML.
Permettez-moi de vous expliquer davantage comment XPath fonctionne.
Voici un exemple. Cette image montre une partie d’un document HTML.
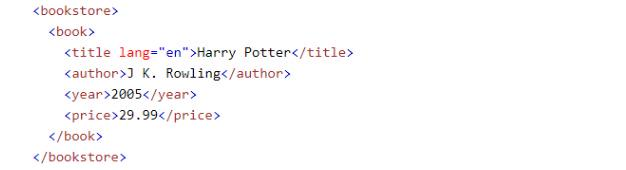
A l’instar d’un arbre, HTML présente les éléments sur différents niveaux. Dans cet exemple, “bookstore” constitue le niveau 1 et “book” le niveau 2. Quant à “title”, “author”, “year”, “price”, il s’agit du niveau 3.
Le texte avec des crochets (<bookstore>) s’appelle une balise (tag en anglais). Chaque élément dans le document HTML est composé de deux balises, une à la tête et l’autre à la fin, tandis que le contenu s’insérant entre les deux.
Soit : <tagname>Le contenu s’insère ici…</tagname>
Au milieu du XPath, le slash “/” est utilisé pour connecter des tags de différents niveaux, de haut en bas, afin de déterminer la location d’un élément. Dans l’exemple mentionné, si nous voulons localiser l’élément ” author “, le XPath serait le suivant :
/bookstore/book/author
Si vous avez des difficultés à comprendre comment cela fonctionne, pensez à ce que nous faisons pour trouver un fichier particulier sur notre ordinateur.

Pour trouver le fichier nommé “author”, le dossier exact est : \bookstore\book\author. Cela vous rappelle quelque chose ?
Chaque fichier sur l’ordinateur a son propre chemin, il en va de même pour les éléments d’une page Web. Avec XPath, vous pouvez trouver les éléments désirés rapidement et facilement, tout comme vous trouvez un fichier sur votre ordinateur.
Le XPath absolu désigne celui qui commence par l’élément racine ( “root element” en anglais, soit l’élément le plus haut dans le document), passe par tous les éléments intermédiaires jusqu’à l’élément cible.
Exemple : /html/body/div/div/div/div/div/div/div/span/span…
Le XPath absolu peut être long, lourd et confus, donc pour simplifier le travail, nous pouvons utiliser “//” pour désigner l’élément par lequel nous voulons commencer le XPath. On nomme ce genre de XPath comme XPath court ou XPath relatif.
Par exemple, le XPath court pour /bookstore/book/author peut être écrit comme //book/author. Ce XPath est capable de repérer l’élément “book”, quelle que soit sa position absolue dans le HTML, puis de trouver l’élément cible “author”.
2. Pourquoi vous devriez connaître XPath lorsque vous utilisez Octoparse ?
Le web scraping avec Octoparse consiste en fait à extraire des éléments à partir des documents HTML et le XPath sert à localiser les éléments cibles.
Prenons l’exemple de l’action de pagination.
Après avoir sélectionné le bouton → pour créer l’action de pagination, Octoparse génère un XPath qui peut localiser le bouton →, afin de savoir sur quel bouton cliquer.
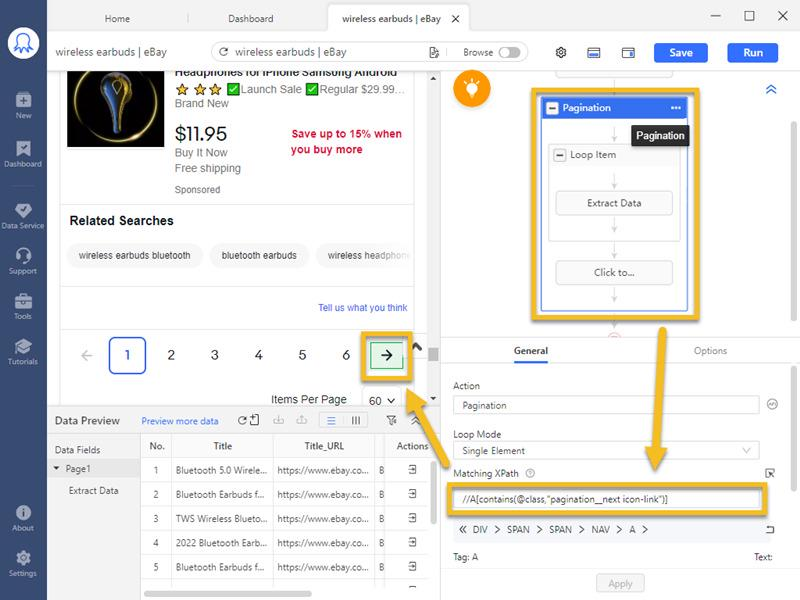
XPath aide le crawler à cliquer sur le bouton exact ou à extraire correctement les données cibles. Chaque action s’exécute en fonction du XPath. Octoparse peut générer des XPaths automatiquement, mais ces derniers ne fonctionnent pas toujours complètement correctement. C’est pourquoi nous devons apprendre à réécrire XPath.
Au cas où vous rencontriez des problèmes tels que des données manquantes, une boucle infinie, des données incorrectes, des données en double, un bouton suivant qui n’est pas cliqué, etc., vous pouvez probablement résoudre ces problèmes facilement en réécrivant le XPath.
3. Comment écrire un XPath
Avant de commencer à écrire un XPath, nous allons d’abord introduire quelques termes clés.
Voici un exemple de HTML que nous allons utiliser pour la démonstration.

Attribut/valeur
Un attribut fournit des informations supplémentaires concernant un élément et il est souvent précisé dans la balise devant l’élément. Un attribut se présente généralement sous forme de nom/valeur, par exemple : name=” valeur “. Certains des attributs les plus ordinaires sont href, title, style, src, id, class, etc.
Vous pouvez trouver l’ensemble des attributs HTML ici.
Dans cet exemple, id=”book” est l’attribut de l’élément <div> et class=”book_name” est l’attribut de l’élément <span>.

Parent/child/sibling
Quand un élément comprend un ou plusieurs sub-éléments HTML, celui qui contient les autres est considéré comme le parent, et les éléments contenus sont comme des enfants du parent. Chaque élément n’a qu’un seul parent, mais un élément parent peut avoir zéro, un ou plusieurs enfants. Les éléments enfants sont placés entre les deux balises de l’élément-parent.
Dans notre exemple, l’élément <body> est le parent des éléments <h1> et <div>. Les éléments <h1> et <div> sont des enfants de l’élément <body>.

Dans le document HTML suivant, l’élément <div> est le parent des deux éléments <span>. Les éléments <span> sont les enfants de l’élément <div>.
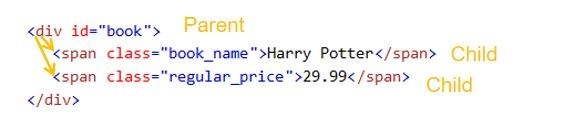
Les éléments qui partagent le même parent sont appelés siblings. L’élément <h1> et l’élément <div> sont des siblings parce qu’ils ont le même parent <body>.
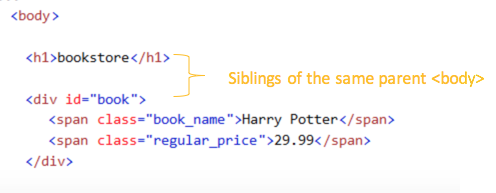
Les deux éléments <span>, qui sont tous deux mis sous l’élément <div>, sont également des siblings.

Voyons quelques cas d’utilisation fréquents !
- ⭕ Écrire un XPath pour localiser le bouton Page suivante
Dans l’exemple HTML ci-dessous, il y a deux choses surlignées. L’un est l’attribut de titre avec la valeur “Next” et deuxièmement, le contenu “Next”.
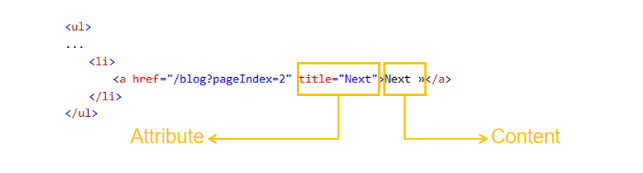
Dans ce cas, nous pouvons utiliser l’attribut de titre ou le texte du contenu pour localiser le bouton Page suivante dans le HTML.
L’XPath capable de repérer l’élément <a> qui a un atribut de titre avec la valeur “Next” ressemblerait à ceci :
//a[@title=”Next”]
Ce XPath veut dire : aller à l’élément <a> dont l’attribut de titre a comme valeur “Next”. Le symbole @ est utilisé dans le XPath pour indiquer un attribut.
Par ailleurs, le XPath capable de repérer l’élément <a> dont le contenu comprend “Next” ressemble à ceci :
//a[contains(text(), “Next”)]
Ce XPath veut dire : aller à l’élément <a> dont le contenu contient le texte “Next”.
Vous pouvez également utiliser l’attribut de titre et le texte contextuel pour écrire le XPath.
//a[@title=”Next” and contains(text(), “Next”)]
Ce XPath veut dire : aller à l’élément ou aux éléments <a> qui ont un attribut de titre avec la valeur “Next” et dont le contenu contient le texte “Next”.
- ⭕ Écrire un XPath pour localiser un élément de boucle
Pour localiser une liste d’éléments sur une page Web, il est avant tout important de rechercher le modèle d’organisation des éléments de la liste. Les éléments d’une même liste partagent généralement des attributs identiques ou similaires. Dans l’exemple HTML ci-dessous, nous constatons que tous les éléments <li> ont des attributs de class similaires.

Cette découverte nous inspire pour utiliser contains(@attribute) pour localiser tous les éléments de la liste.
//li[contains(@class,”product_item”)]
Ce XPath veut dire : aller à l’élément ou aux éléments <li> dont l’attribut de class contient “produit_item”.
- ⭕ Écrire un XPath pour localiser des champs de données
Le processus de localiser un champ de données particulier est très similaire à celui de localiser le bouton Page suivante en utilisant text() ou l’attribut.
Pour cet exemple :

Imaginons que nous voulions écrire un XPath pour localiser l’adresse dans l’exemple HTML ci-dessus.
Nous pouvons utiliser l’attribut de itemprop qui a pour valeur “address” pour localiser l’élément particulier.
//div[@itemprop=”address”]
Ce XPath veut dire : aller à l’élément <div> dont l’attribut de itemprop a pour valeur “address”.
En outre, on remarque que l’élément <div> contenant l’adresse réelle se trouve toujours derrière son élément frère <div> qui contient le contenu “Location :”. Donc, nous pouvons d’abord localiser le texte ” Location “, puis sélectionner le premier sibling qui le suit.
//div[contains(text(),”Location”)]/following-sibling::div[1]
Ce XPath veut dire : aller à l’élément <div> dont le contenu contient ” Location “, puis aller à son premier élément <div> frère.
Maintenant, vous avez probablement remarqué qu’il y a en fait plus d’une façon de positionner un élément dans le texte HTML. C’est le cas. L’essentiel consiste à utiliser la balise, les attributs, le texte du contenu, les siblings, le parent, tout ce qui peut vous aider à localiser l’élément désiré dans le texte HTML.
Pour vous faciliter la tâche, voici un aide-mémoire des expressions XPath utiles pour vous aider à localiser rapidement les éléments dans le texte HTML.
| Expression | Example | Meaning |
| * Matches any elements | //div/* | Selects all the child element of the <div> element |
| @ Selects attributes | //div[@id=”book”] | Selects all the <div> elements that have an “id” attribute with a value of “book” |
| text() Finds elements with exact text | //span[text()=”Harry Potter”] | Selects all the <span> elements whose content is exactly “Harry Potter” |
| contains() Selects elements that contain a certain string | //span[contains(@class, “price”)] | Selects all the <span> elements whose class attribute value contains “price” |
| //span[text(),”Learning”] | Selects all the <span> elements whose content contains “Learning” | |
| position() Selects elements in a certain position | //div/span[position()=2]//div/span[2] | Selects the second <span> element that is the child of the <div> element |
| //div/span[position()<3] | Selects the first 2 <span> elements that are the child of <div> element | |
| last() Selects the last element | //div/span[last()] | Select the last <span> element that is the child of <div> element |
| //div/span[last()-1] | Selects the last but one <span> element that is the child of <div> element | |
| //div/span[position()>last()-3] | Selects the last 3 <span> elements that are the child of <div> element | |
| not Selects elements that are opposite to the conditions specified | //span[not(contains(@class,”price”))] | Selects all the <span> elements whose class attribute value does not contain price |
| //span[not(contains(text(),”Learning”))] | Selects all the <span> elements whose text does not contain “Learning”. | |
| and Selects elements that match several conditions | //span[@class=”book_name” and text()=”Harry Potter”] | Selects all the <span> elements whose class attribute value is “book_name” and the text is “Harry Potter” |
| or Selects elements that match one of the conditions | //span[@class=”book_name” or text()=”Harry Potter”] | Selects all the <span> elements whose class attribute value is “book_name” or the text is “Harry Potter” |
| following-sibling Selects all siblings after the current element | //span[text()=”Harry Potter”]/following-sibling::span[1] | Selects the first <span> element after the <span> element whose text is “Harry Potter” |
| preceding-sibling Selects all siblings before the current element | //span[@class=”regular_price”]/preceding-sibling::span[1] | Selects the first <span> element before the <span> element whose class attribute value is “regular_price” |
| .. Selects the parent of the current element | //div[@id=”bookstore”]/.. | Select the parent of the <div> element whose id attribute value is “bookstore” |
| | Selects several paths | //div[@id=”bookstore”] | //span[@class=”regular_price”] | Selects all the <div> elements whose id attribute value is “bookstore” and all the <span> elements whose class attribute value is “regular_price”. |
Cliquez ici pour avoir accès à une liste d’expressions plus riche.
4. Matching XPath et XPath relatif (quand il s’agit de la boucle)
Nous avons appris à écrire un XPath quand on veut extraire directement un élément d’une page Web. Il arrive cependant que vous devriez d’abord décider une liste d’éléments et puis y extraire quelques éléments ou tous les éléments.
Site d’exemple https://www.bestbuy.com/site/promo/tv-deals
Pour récupérer les résultats de recherche, vous devez non seulement connaître le matching XPath (lequel vous utilisez pour extraire directement les éléments), mais aussi le XPath relatif, celui qui aide à extraire des élément dans la liste.
Matching XPath est mis en application quand nous voulons extraire les données directement de la page web.
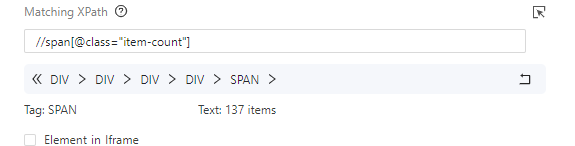
Le workflow de la sorte est comme suivant.

N.B. : Le matching Xpath est différent du XPath absolu. Ce dernier se présente sous une forme compliquée et lourde, comme “/html/body/div/div/div/div/div/span/span…”, tandis que le matching xpath veut dire que les données récupérées ne sont pas retirées à partir d’une boucle. Le matching XPath peut également être simplifié comme “//h1[@class=”…”]/span[2]…”.
Le XPath relatif est utilisé lorsque nous extrayons des données d’un élément de boucle.
Plus précisément, lorsque nous créons un flux de travail comme celui-ci :
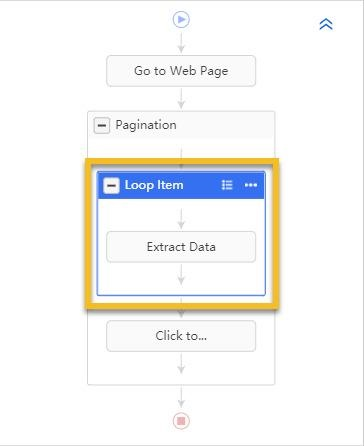
Le XPath relatif est une partie supplémentaire du matching XPath de l’élément voulu par rapport au XPath de la boucle dans laquelle se trouve l’élément voulu.

Par exemple, pour ce HTML, notre objectif est de créer une liste d’éléments <li> en boucle et d’extraire un sub-élément contenu dans la boucle.
Nous pouvons localiser la liste avec le XPath //ul[@class=”results”]/li et quant à un des sub-éléments dans cette liste, on écrit //ul[@class=”results”]/li/div/a[@class=”link”].
Dans ce cas, l’XPath relatif est /div/a[@class=”link”]. Nous pouvons aussi simplifier ce XPath relatif en utilisant “//” pour obtenir //a[@class=”link”]. Il est toujours recommandé d’utiliser “//” lors de l’écriture d’un XPath relatif, car cela rend l’expression plus précise.
Essayons de faciliter la relation entre les différents XPaths.
XPath de la boucle : //ul[@class=”résultats”]/li
XPath de l’élément que vous voulez localiser dans la boucle des éléments : //ul[@class=”results”]/li/div/a[@class=”link”]
XPath relatif à la boucle : /div/a[@class=”link”]
Nous devrions ensuite entrer le XPath de l’élément de boucle et le XPath relatif comme ceci dans Octoparse :
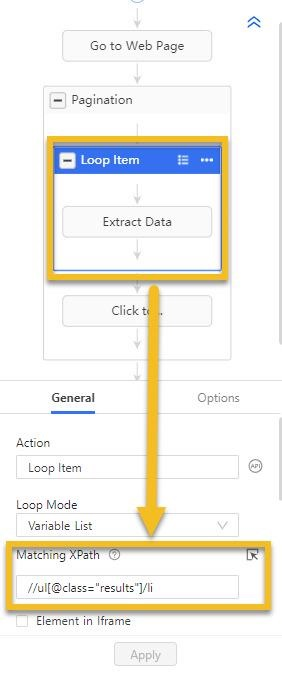
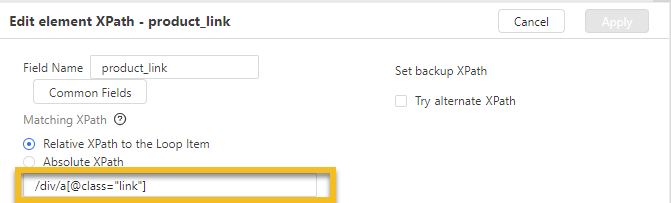
Évidemment, en combinant le XPath de la liste et le XPath relatif, vous obtiendrez exactement le XPath de l’élément.
5. 4 étapes simples pour corriger votre XPath
Étape 01 :
Ouvrez la page Web à l’aide d’un navigateur équipé d’un outil XPath (qui vous permet de voir le code HTML et de rechercher une requête XPath). Pemettez-moi de vous recommender Le XPath Helper (une extension Chrome) si vous utilisez Chrome.
Étape 02 :
Une fois la page Web chargée, cliquez droit l’élément cible et l’inspectez dans le HTML.
Étape 03 :
Inspectez de près l’élément HTML et les éléments à proximité. Voyez-vous quelque chose qui se démarque et qui pourrait vous aider à identifier et à localiser l’élément cible ? Peut-être un attribut de class comme class=”sku-title” ou class=”sku-header” ?

Utilisez la feuille de triche ci-dessus pour écrire un XPath qui sélectionne l’élément exclusivement et précisément. Votre XPath ne doit correspondre qu’au(x) élément(s) cible(s) et à rien d’autre. Avec XPath Helper, vous pouvez toujours vérifier si le XPath réécrit fonctionne correctement.
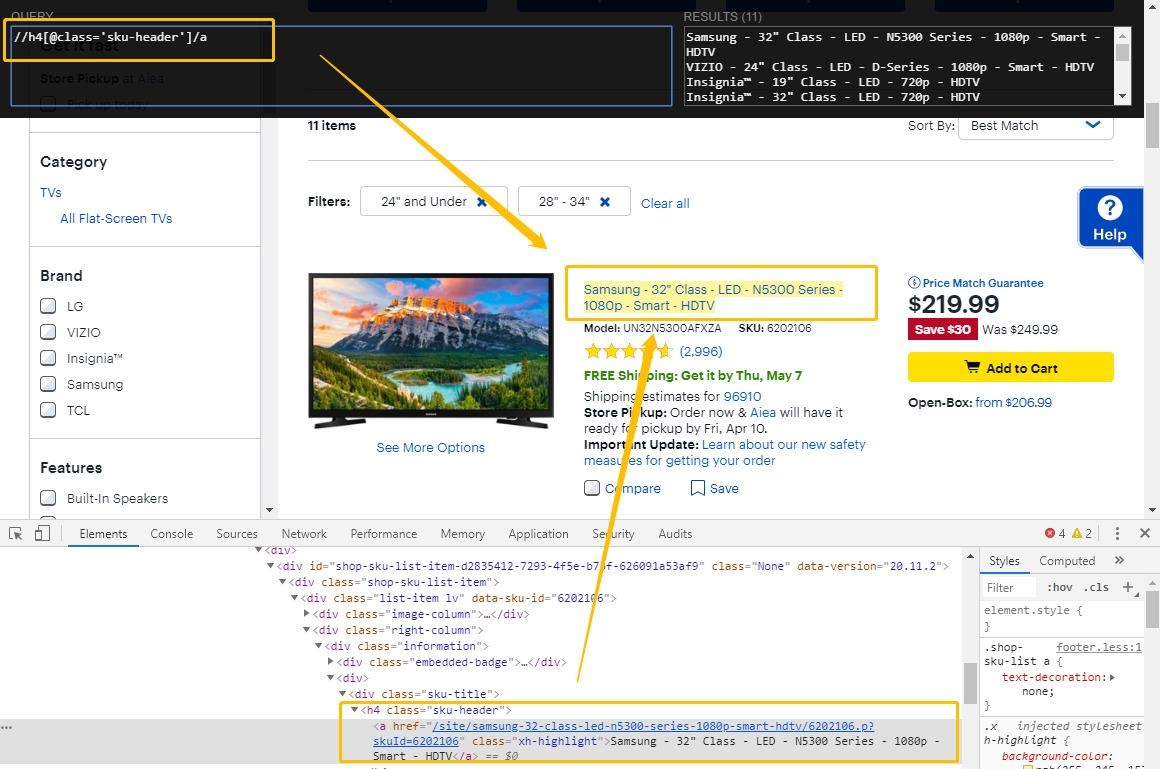
Étape 4 :
Remplacez le XPath généré automatiquement dans Octoparse avec celui que vous venez d’écrire.
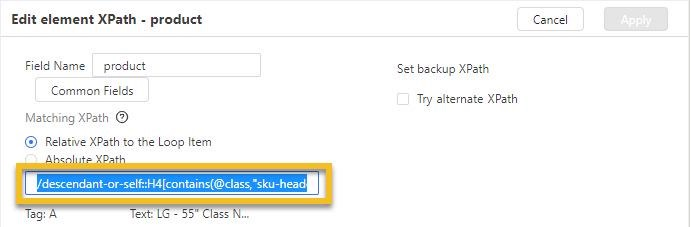
Plus de tutoriels étape par étape :
- Personnaliser l’XPath des éléments
- Localiser et extraire un élément par le texte à proximité 6. Outils de XPath
Il n’est pas facile de vérifier si le XPath est correct dans Octoparse et c’est pourquoi il faut mettre en application des autres outils qui nous aideront à écrire un XPath correct.
# Octoparse XPath tool
Octoparse fournit un outil de XPath qui aide les utilisateurs d’écrire le XPath facilement.
# Chrome ou tout navigateur
Vous pouvez obtenir le XPath d’un certain élément avec tout genre de navigateur très facilement.
- Ouvrir la page Web dans Chrome
- Faire un clic droit sur l’élément dont le XPath est à votre besoin
- Choisir ” Inspecter ” et vous verrez Chrome DevTools
- Faire un clic droit sur le zone surligné
- Copier XPath
Mais il est souvent le cas que le XPath obtenu est un XPath absolu et qu’il n’y a pas d’attributs ou que la valeur des attributs est trop longue. Et vous devriez encore d’écrire le XPath correct.
# XPath Helper
Il s’agit d’une super chrome extension qui permet d’inspecter le XPath en simplement passant la souris sur l’élément voulu. Et vous pouvez aussi modifier le XPath dans le console. Avec les résultats immédiats, vous pouvez savoir très vite si le XPath fonctionne ou pas.
Vous pouvez le télécharger ici.
发表回复