
Uber Eats, qui est un fournisseur de service de livraison de plats cuisinés, contient un océan de données qui sont d’une valeur considérable si on sait comment mieux en profiter. Dans cet article, on essaie d’exploiter en profondeur les données Uber Eats et de montrer comment scraper gratuitement les données Uber Eats pour l’analyse antérieure.
Pourquoi scraper les données Uber Eats ?
Les habitudes de consommation changent
Pourquoi les données à propos de la livraison de repas sont-elles aussi importantes ? Croyez-le ou non, la plupart des gens ont vécu cette expérience : se trouver trop fatigué ou trop occupé pour cuisiner ou sortir manger, puis ouvrir des applications ou sites de livraison de nourriture, et finir par déguster un repas délicieux dans leur pyjama, confortablement.
A cause de la demande croissante et du climat culturel, les restaurants qui ne proposent pas de livraison de nourriture risquent de prendre du retard sur leurs concurrents. Pour rester en tête du secteur, les commerçants doivent s’adapter à ces changements dans les habitudes des consommateurs.
Des manières de profiter des données Uber Eats
En effet, ces données couvrent une valeur considérable, tant pour les commerçants que pour les consommateurs. Les commerçants ont besoin d’un nombre énorme de données qui sont à la base des recherches du marché, tandis que les clients, surtout les gastronomes ou les gourmands qui sont passionnés pour recommender des plats délicieux, peuvent avoir recours au webscraping pour obtenir des données à grande échelle, aidant à localiser les meilleurs restaurants et à élargir l’éventail des recommandations.
Voilà des idées pour utiliser les données Uber Eats :
✔️ Propriétaires de restaurants physiques : ils peuvent étendre l’activité au service de livraison. Avant de vous inscrire sur une grande plateforme de livraison de nourriture, il faut explorer les services similaires des commerçants locaux de votre région pour faire une analyse sur la concurrence actuelle et évaluer l’espace du marché.
✔️ Propriétaires de restaurants virtuels : ils peuvent analyser en profondeur la concurrence. En se comparant aux produits offerts par les autres, on peut optimiser ses offres et y ajouter aussi des autres nourritures attrayantes. Cela est peut-être un excellent moyen de stimuler les ventes. De plus, les détaillants ayant une image de marque positive vont voir une augmantation des ventes des autres produits qu’ils vendent.
✔️ Gastronomes : les clients, et surtout les gastronomes ou les gourmands qui sont passionnés pour recommender des plats délicieux, peuvent avoir recours au webscraping pour obtenir des données à grande échelle, aidant à localiser les meilleurs restaurants et à élargir l’éventail dse recommandations.
Quels champs de données à récupérer ?
Nom de restaurant
Adresse
Délai de livraison
Frais de livraison
Rating (Note d’évaluation)
Temps d’ouverture
Nom de catégories
Nom de sélection et prix de sélection
…
En un mot, tout ce qui est affiché sur la page peut être obtenu à travers le web scraping.
Trois étapes pour scraper Uber Eats gratuitement avec le web scraping
Faire des préparations nécessaires :
Télécharger Octoparse et installer le logiciel sur votre ordinateur (Windows/Mac)
S’inscrire et obtenir un compte d’Octoparse
Cibler l’URL Uber Eats à partir de laquelle vous allez récupérer les données de livraison de repas
En trois étapes, vous pouvez créer un Uber Eats scraper vous-même à l’aide de l’Octoparse.
Lancez le logciel, entrez l’URL cible dans la barre de recherche et cliquez sur le bouton “Start”. Et vous pouvez voir la page Web qui se charge dans le navigateur intégré d’Octoparse.
URL d’exemple :
Étape 1 Sélectionner les données que vous souhaitez collecter
Tout d’abord, vous devez fermer les fenêtres pop-up qui peuvent affecter le processus de scraping. Cliquez sur le bouton “Browse” dans le coin supérieur droit, et puis fermez les fenêtres pop-up comme vous le faites normalement. Le site Uber Eats demande aux internautes de se connecter d’abord. Donc, cliquez sur “Connection” sous le mode de navigateur pour vous connecter à votre compte Uber. Après ces opérations, vous pouvez passer en mode de scraping en cliquant à nouveau sur le bouton “Browse”.
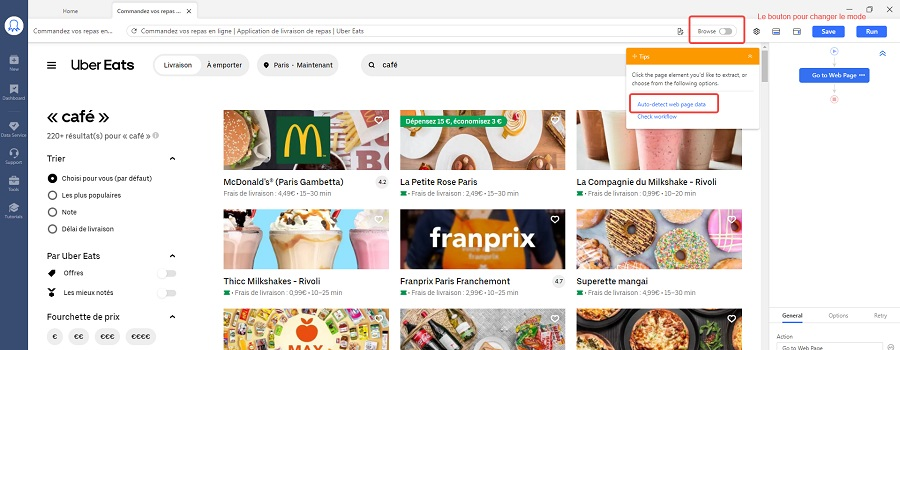
Comme vous pouvez le voir, il y a un panneau de Tips. Si on clique sur “Auto-detect web page data”, le robot d’Octoparse peut analyser la page Web et sélectionner automatiquement les données que vous êtes susceptible de souhaiter collecter. Une fois l’auto-détection terminée, les données récupérées sont affichées dans la section “Data Preview” en dessous et il est à vous de supprimer des champs de données selon vos besoins.
Étape 2 Créer le workflow de ce Uber Eats scraper
Cliquez sur “Create workflow” et vous pouvez voir le flux de travail à droite.
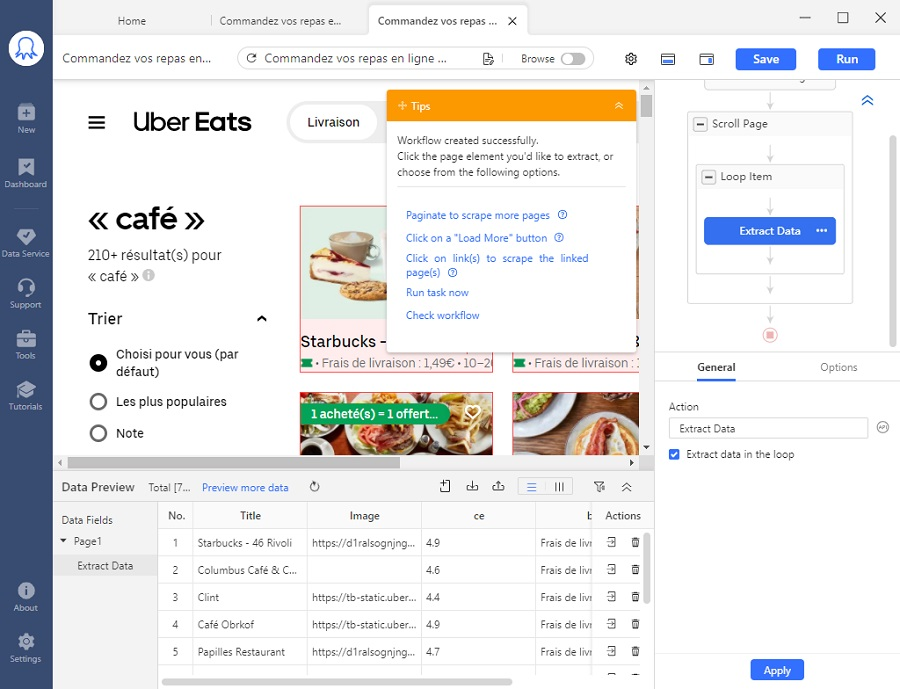
Il se peut que les résultats de l’auto-détection ne correspondent pas complètement à vos besoins. Ne vous inquiétez pas car vous pouvez toujours corriger le XPath pour localiser les données manquantes. Puisque XPath est un sujet inévitable dans le web scraping, nous offrons un tutoriel pour faire comprendre complètement qu’est-ce que XPath et comment utiliser dans Octoparse. Si vous avez des questions sur XPath, n’hésitez pas à contacter le support.
Vous direz peut-être que les données de la page de liste ne conviennent pas encore à votre besoin de faire des recherches sur la livraison de repas ou de savoir quelle est la meilleure nourriture à vos côtés. Dans ce cas, Octoparse est là pour vous aider à extraire les données des pages de détail sur Uber Eats.
En raison des caractéristiques du site Uber Eats, vous pouvez effectuer le web scraping par deux tâches.
Pour recueillir les données sur les pages de détail, vous devez cliquer sur l’image de chaque restaurant pour entrer dans les pages de détail et sélectionner les éléments que vous souhaitez extraire. Par conséquent, vous devez ajouter une étape pour extraire les URL des restaurants à l’avance. Cliquez sur une image de restaurant, sélectionnez la balise “A” dans le panneau de Tips, puis cliquez sur “Extract the URL of the selected link”.
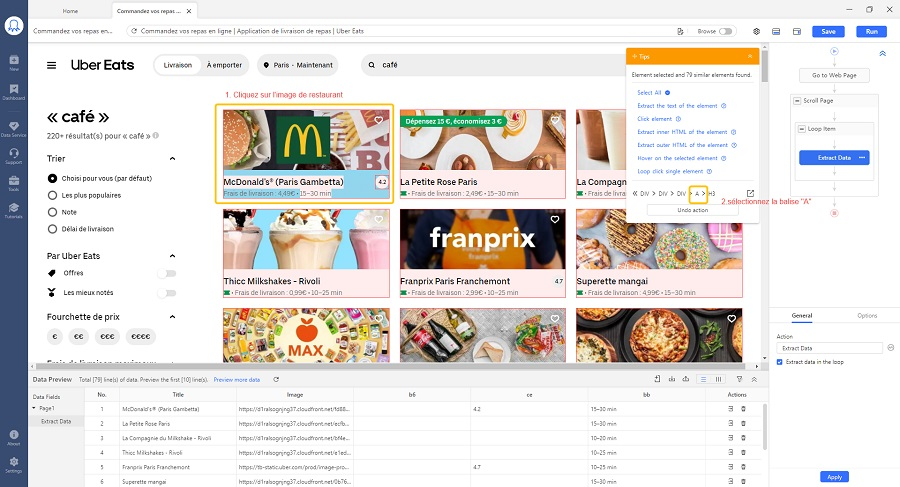
Ensuite, cliquez sur “Run” et Octoparse commencera alors à extraire les données. Les utilisateurs de la version gratuite ne peut faire exécuter la tâche que sur l’ordinateur local, et pour les abonnés des plans payants, l’extraction sur le cloud sera disponible. En outre, vous pouvez également planifier les tâches pour qu’elles s’exécutent chaque jour/semaine/mois. N’oubliez pas d’enregistrer les cookies avant d’exécuter la tâche.
Avec une longue liste de URL à la main, on peut maintenant créer une nouvelle tâche pour extraire les informations sur la page de détail.
Cliquez sur “+ New” > “Advanced Mode”, copiez et collez la liste d’URL, cliquez “Save”.
Note : Octoparse permet aux utilisateurs d’importer jusqu’à un million d’URL. et on peut importer des URL à partir d’un fichier, d’une autre tâche ou générer par lots des URL basées sur un modèle prédéfini. Un tutoriel est disponible pour le sujet entrer des URLs par lot.
Maintenant que le nouveau workflow est créé, vous pouvez sélectionner n’importe quel élément que vous souhaitez extraire sur les pages de détail manuellement ou automatiquement.
Étape 3 Exécuter la deuxième tâche et extraire les données à partir des pages de détail
Cliquez sur “Run” après que le workflow est fini. Dans Octoparse, les utilisateurs peuvent télécharger ou extraire les données vers n’importe quelle base de données ou vers des fichiers JSON, XLS, CSV ou HTML.
Octoparse vous offre aussi un tutoriel de vidéo étape par étape, des XPath utiles inclus, et je suis sûr que cela vous aider grandement.
Avec l’essor de l’industrie de la livraison de repas à domocile, les commerçants et les consommateurs voient un besoin croissant des données en la matière. Allez télécharger Octoparse et commencer votre journée de web scraping. Au cas où des questions se posent, n’hésitez pas à nous contacter.
发表回复