
À mesure que les philosophies de l’intelligence artificielle et du big data se répandent, il se peut que vous ayez besoin d’extraire des données à partir d’un grand nombre de liens. L’extraction de tous les liens sur la page Web est la toute première chose et la plus importante dans ce terme. C’est par là qu’on peut explorer chaque URL afin de rassembler divers éléments Web, tels que des images, du texte ou des liens dans l’hyperlien, en vue d’une analyse plus approfondie.
Un extracteur de liens intelligent peut considérablement améliorer l’efficacité de l’extraction de données, ce qui est essentiel pour l’analyse SEO, l’analyse de la concurrence, la création de contenu, etc. Dans cet article, nous vous présenterons les 10 meilleurs extracteurs de liens à ne pas manquer.
10 meilleurs outils pour extraire les liens
TOP 1 : Octoparse (le plus facile à utiliser)
Octoparse est un outil de web scraping puissant et gratuit qui vous permet d’extraire du HTML interne/externe et des liens à partir de différents champs de balises. Il s’agit d’une solution sans code qui permet à tout le monde de récupérer des données sans écrire la moindre ligne de code.
Les hyperliens sont des URL cliquables qui ouvrent de nouvelles pages ou vous dirigent vers de nouveaux sites Web. Lorsque vous obtenez des URL, vous pouvez accéder et télécharger le fichier ou l’image correspondant via ces liens. Pour extraire les liens avec Octoparse, vous n’avez qu’à cliquer sur vos données cibles et à sélectionner Lien dans le panneau Conseils.
Veuillez continuer avec ce guide pour savoir les étapes complètes d’extraire les données avec Octoparse.
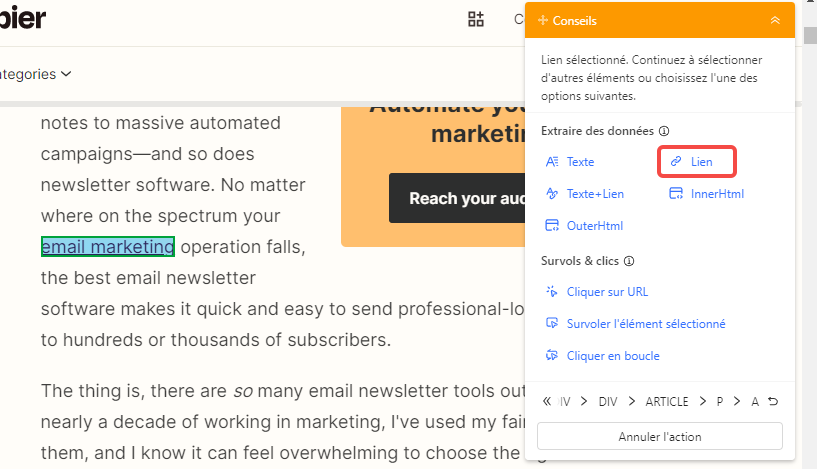
Cet outil est fréquemment utilisé dans l’extraction de liens des images. Il vous suffit de cliquer sur l’image et puis sélectionner Image URL dans le panneau de conseils.
En tant que logiciel de web scraping, Octoparse est loin d’être justement un extracteur de lien. Il peut extraire tous les éléments depuis des pages Web, y compris texte, tableau, lien, image, etc. Quelques étapes sont suffisantes pour créer un web scraper à vous-même avec cet outil totalement nocode.
TOP 2 : Apify
Apify est également une plateforme de scraping web. Les utilisateurs peuvent y trouver des outils et des modèles de code prêts à l’emploi pour extraire des données de sites web. De nombreux extracteurs de liens sont conçus et téléchargés par des développeurs disponibles sur Apify, et la plupart d’entre eux sont conviviaux et vous permettent de gérer des tâches de web scraping sans connaissances approfondies en programmation. Toutefois, si vous n’avez aucune expérience en matière de codage, la courbe d’apprentissage risque d’être abrupte.
TOP 3 : Bright Data
Bright Data est une société qui propose des services de collecte de données web aux entreprises B2B. Elle met à la disposition des utilisateurs divers outils et API pour la collecte de données web à des fins diverses. L’URL Scraper de Bright Data est prédéfini et vous pouvez l’utiliser pour collecter des URL à partir de sites de commerce électronique, de médias sociaux, de sites Web immobiliers, etc. Mais attention au coût. L’utilisation des services de Bright Data peut s’avérer coûteuse si vous avez des besoins de scraping importants ou intensifs.
TOP 4 : WebHarvy
WebHarvy est un logiciel de scraping web par pointer-cliquer qui permet aux utilisateurs d’extraire des données web, y compris des URL, en toute simplicité. Lorsque vous scrapez des URL à l’aide de WebHarvy, vous pouvez utiliser son expression régulière prédéfinie pour obtenir des liens à partir du code HTML plutôt que d’en écrire une vous-même.
TOP 5 : Link Grabber
Link Grabber est un extracteur, en particulier pour les liens hypertextes sur les pages HTML. Comme il s’agit d’une extension Chrome, il est léger et facile à utiliser. Il peut également filtrer les liens par correspondance de chaîne de caractères et regrouper les liens par domaine, ce qui vous permet de gagner du temps pour nettoyer les données extraites. Mais il ne peut extraire que des liens sur des sites web, si vous avez besoin de plus de données comme du texte et des images, ce n’est probablement pas le meilleur choix.
TOP 6 : Link Gopher
Il s’agit d’un autre outil léger qui se concentre sur l’extraction de liens. Il peut extraire tous les liens d’une page web, y compris les liens intégrés, les trier, supprimer les doublons et les afficher dans un nouvel onglet pour les copier-coller. L’utilisation de cet outil pour extraire des liens ne nécessite qu’un seul clic pour choisir l’option Extraire, et vous pouvez alors obtenir les URL que vous souhaitez. Cependant, comme nous l’avons mentionné, vous ne pouvez pas exporter directement les liens extraits dans des fichiers, mais vous pouvez les copier et les coller dans d’autres systèmes.
TOP 7 : Link Klipper
Link Klipper est l’un des extracteurs de liens les plus populaires du Chrome Web Store. Simple mais puissant, il vous permet d’extraire tous les liens d’une page web et de les exporter dans un fichier. Vous pouvez personnaliser une zone du site web et extraire tous les liens de cette zone en fonction de vos besoins. Toutefois, cette extension ne permet d’exporter toutes les données extraites que sous la forme d’un fichier CSV. Si vous avez besoin de stocker des données dans d’autres formats à des fins d’analyse, vous devez consacrer plus de temps à la conversion du format CSV.
TOP 8 : Beautiful Soup (Python)
Beautiful Soup est une bibliothèque Python populaire qui permet d’extraire des données de fichiers HTML et XML. Elle peut bien gérer un HTML mal formaté et fournit une API simple et intuitive pour naviguer et extraire des données de documents HTML. Si vous êtes familier avec le codage, il peut s’agir d’une méthode flexible et efficace. Voici un exemple de code qui montre comment Beautiful Soup récupère les liens d’un site web.
from bs4 import BeautifulSoup
# Sample HTML content
html_doc = """
<html>
<head><title>Example Page</title></head>
<body>
<a href="https://www.example.com">Example Link</a>
<a href="https://www.example.com/page2">Another Link</a>
</body>
</html>
"""
# Create a Beautiful Soup object
soup = BeautifulSoup(html_doc, 'html.parser')
# Find all links (anchor tags)
links = soup.find_all('a')
# Extract and print link URLs
for link in links:
print(link.get('href'))TOP 9 : Scrapy (Python)
Scrapy est un outil puissant et flexible d’exploration et de récupération de données sur le web, écrit en Python. Vous pouvez trouver dans Scrapy un ensemble complet d’outils pour l’extraction de données, y compris des liens. L’un des principaux avantages de Scrapy est qu’il est bien adapté aux tâches de scraping à grande échelle, qu’il prend en charge le crawling distribué et qu’il gère efficacement les scénarios complexes. Vous trouverez ci-dessous un exemple de code pour l’extraction de liens à l’aide de Scrapy.
import scrapy
class LinkSpider(scrapy.Spider):
name = 'link_spider'
start_urls = ['https://www.example.com']
def parse(self, response):
# Extracting links using CSS selector
links = response.css('a::attr(href)').extract()
for link in links:
print(link)TOP 10 : Selenium (Différentes langues)
Selenium est connu comme un outil d’automatisation web utilisé pour tester des applications. Mais il peut également être utilisé pour des tâches de web scraping. Par rapport à d’autres bibliothèques Python, Selenium visualise le processus de scraping, ce qui facilite le débogage et la vérification des liens extraits. Cependant, en termes de vitesse de scraping, Selenium peut être relativement plus lent que Beautiful Soup ou Scrapy, en particulier pour les tâches de scraping à grande échelle.
from selenium import webdriver
# Set up the WebDriver (e.g., for Chrome)
driver = webdriver.Chrome()
# Load a webpage
driver.get("https://www.example.com")
# Find all links on the page
links = driver.find_elements_by_tag_name('a')
# Extract and print link URLs
for link in links:
print(link.get_attribute('href'))
# Close the browser
driver.quit()En conclusion
L’extraction de liens joue un rôle essentiel dans les études de marché. Elle permet de collecter des données pour la recherche, l’analyse SEO, la génération de leads, etc. En outre, il soutient les études de marché et la surveillance de la marque qui contribuent aux stratégies de marketing et aux efforts de conformité. Quel que soit votre secteur d’activité, vous pouvez tirer profit de l’utilisation d’extracteurs de liens. J’espère que vous trouverez les bons outils de link scraping dans cet article et que vous stimulerez votre activité à l’aide du web scraping.
发表回复